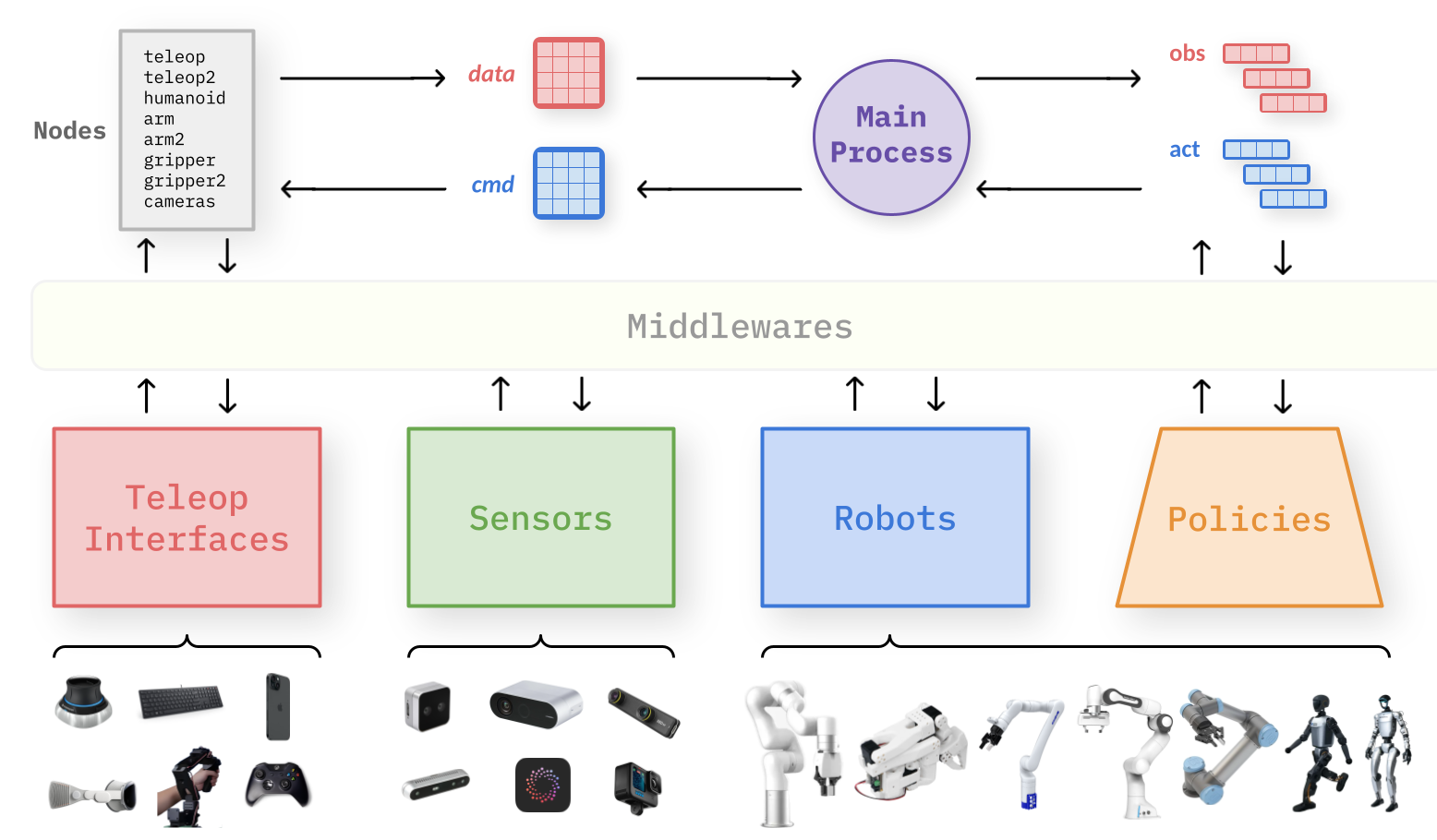
| Humanoid Robots | Unitree G1, Booster T1 |
| Robot Arms | UFactory (xArm5/6/7, 850, Lite6), UR (UR5e, UR7e), Franka (FR3, Panda), Kinova (Gen3), SO-100/SO-101 |
| Robot Grippers | UFactory, Franka, Robotiq (2F-85/2F-140), DH-Robotics (AG-105-145) |
| Teleop Interfaces | Spacemouse, Gamepad, Keyboard, VR (Apple Vision Pro, Meta Quest), Leader-Follower (GELLO), Phone |
| Cameras | RealSense, ZED, UVC (Webcams, USB), iPhone (Record3D) |
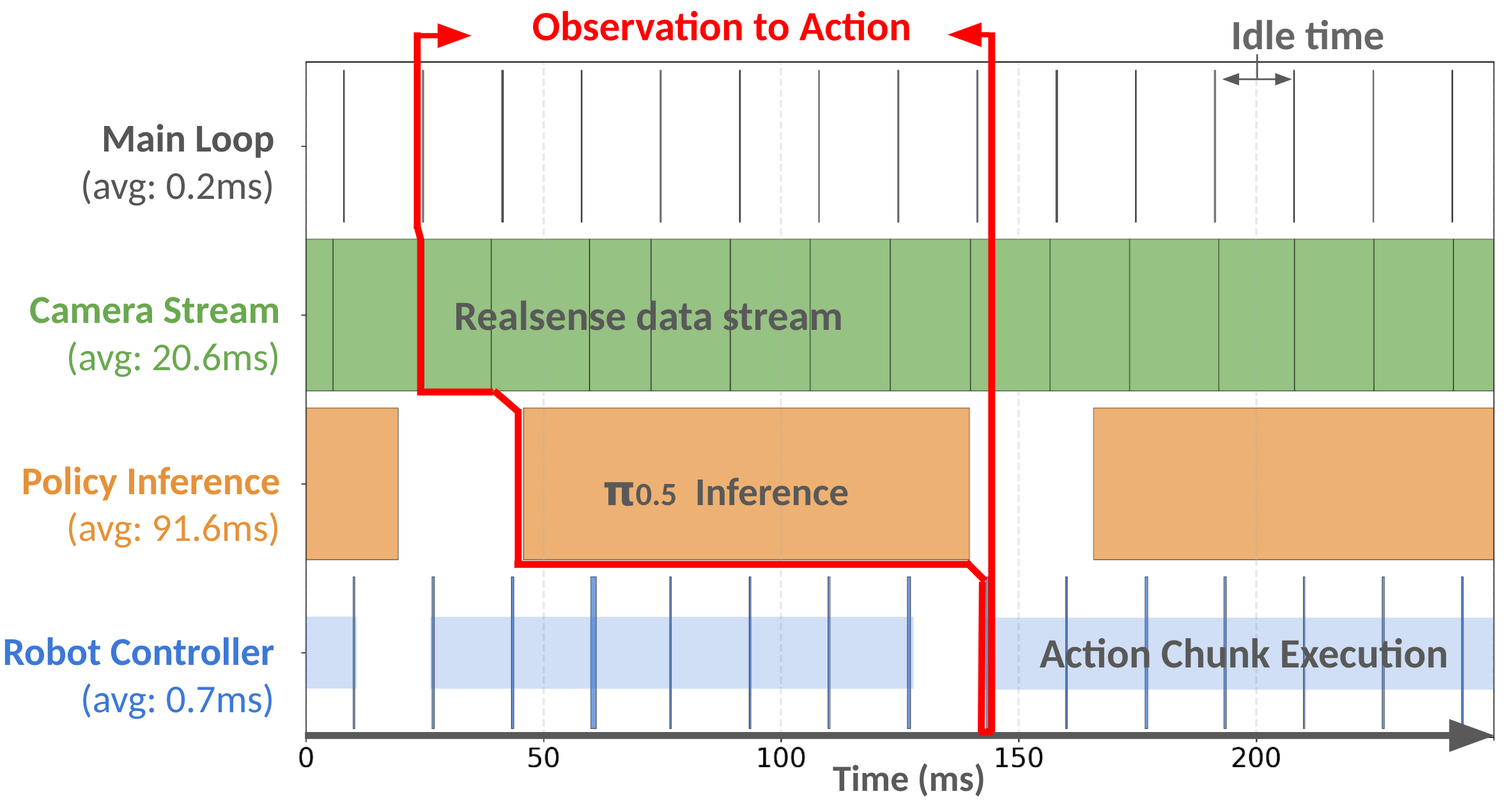
| Middlewares | Shared Memory, Thread, Portal, Zenoh, ZeroRpc |
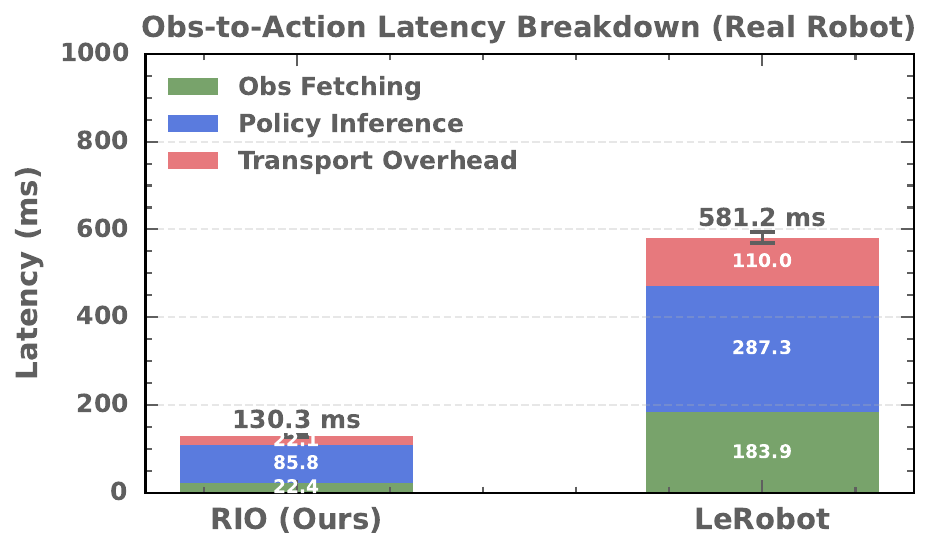
Robot Stations
A composable dataclass configuration specifies the hardware topology for each station. The same application logic operates over arbitrary station configurations without modification.

Example robot station configurations combining different hardware, sensors, and teleoperation interfaces.